Inspiration
Engaging in text embeddings research, I’ve delved into exploring the nuanced relationships between specific words and phrases. Grateful for the insights gained from the OpenAI course that sparked my interest in this domain.
Analyzed Data and Models
For the analysis, I selected eight pairs of qualitative words, each representing distinct domains such as temperature, physical dimensions, intellect, and mood. The pairs include antonyms for each domain, like ‘Hot-Cold’ and ‘Freezing-Boiling’ for temperature. The complete list of words is as follows:
- Temperature: Hot,Cold,Freezing,Boiling
- Physical dimensions: Long,Short,Wide,Narrow
- Intellect: Smart,Stupid,Intelligent,Ignorant
- Mood: Happy,Sad,Relaxed,Tense
I examined the evolution of text embedded models, specifically comparing the oldest (gecko@001) to the newest (gecko@003) models available on VertexAI.
| textembedding-gecko model | Release date | Discontinuation date |
|---|---|---|
| textembedding-gecko@003 | December 12, 2023 | Not applicable |
| textembedding-gecko@002 | November 2, 2023 | Not applicable |
| textembedding-gecko-multilingual@001 | November 2, 2023 | Not applicable |
| textembedding-gecko@001 | June 7, 2023 | Not applicable |
Metrics
 Understandably we are loosing a lot of precision when trying to reduce the number of dimensions from 768 to just 2.
Understandably we are loosing a lot of precision when trying to reduce the number of dimensions from 768 to just 2.
That might be one of the weak points of the research, however I utilized the following distance measures:
- Principal component analyzis, PCA2 (reduction from 768 features to 2)
- Cosine distances
- Manhattan distances
Results
The comparison yielded the following results (old model at the left, new model at the right):
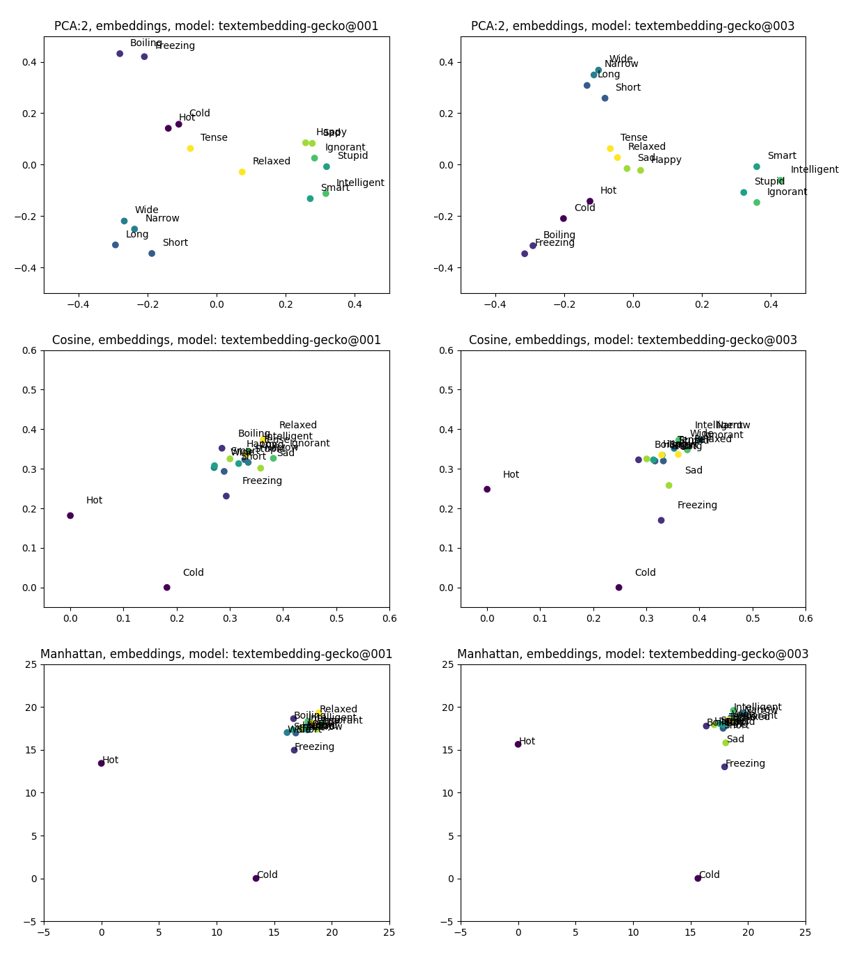
Two notable conclusions emerged from the observations:
- The latest model exhibits clearer clusters, particularly denser grouping of ‘mood’ words.
- Certain words, such as ‘Hot’ and ‘Cold,’ appear to stand apart in both models, possibly due to their frequency and connections.
The juxtaposition of ‘Relaxed intelligent’ versus ‘Tense temperature’ trends seems to be subdued in the latest model :)
Exploring how words and phrases relate in embedded models is a fascinating endeavor. If you have valuable insights or wish to compare your models, feel free to use my code provided below and share your thoughts.
Instructions and Code
To begin, create a Google Cloud account, register your project, and locally store a .json API key for VertexAI authorization. In my project, the API key is stored in the ‘keys’ folder at the root.
from google.auth.transport.requests import Request
from google.oauth2.service_account import Credentials
from sklearn.decomposition import PCA
from sklearn.metrics.pairwise import cosine_distances, euclidean_distances, manhattan_distances
import vertexai
import os
import numpy as np
import matplotlib.pyplot as plt
# Path to your service account key file
key_path = "\\keys\\project-03042024-60650bc6b71b.json"
# Path to the json key associated with your service account from google cloud
# Create credentials object
credentials = Credentials.from_service_account_file(
os.getcwd() + key_path,
scopes=['https://www.googleapis.com/auth/cloud-platform'])
if credentials.expired:
credentials.refresh(Request())
PROJECT_ID = 'project-03042024'
REGION = 'us-central1'
# initialize vertex
vertexai.init(project=PROJECT_ID,
location=REGION,
credentials=credentials)
def embed_2d_compare(model_name,
input_text_list, # Should be even length (pairs)
distance_type,
pre_title="embeddings, model: ",
xlim_min=-0.5,
xlim_max=0.5,
ylim_min=-0.5,
ylim_max=0.5
):
from vertexai.language_models import TextEmbeddingModel
embedding_model = TextEmbeddingModel.from_pretrained(
model_name)
embeddings = []
for input_text in input_text_list:
emb = embedding_model.get_embeddings(
[input_text])[0].values
embeddings.append(emb)
embeddings_array = np.array(embeddings)
# Python supports match starting from version 3.10
if distance_type == 'cosine':
new_values = cosine_distances(embeddings_array)
pre_title = 'Cosine, ' + pre_title
elif distance_type == 'euclidian':
new_values = euclidean_distances(embeddings_array)
pre_title = 'Euclidian, ' + pre_title
elif distance_type == 'manhattan':
new_values = manhattan_distances(embeddings_array)
pre_title = 'Manhattan, ' + pre_title
else:
# Perform PCA for 2D visualization
PCA_model = PCA(n_components=2)
PCA_model.fit(embeddings_array)
new_values = PCA_model.transform(embeddings_array)
pre_title = 'PCA:2, ' + pre_title
plt.scatter(new_values[:, 0],
new_values[:, 1],
c=[x for x in range(1, int(len(input_text_list)/2) + 1) for _ in range(2)])
# generates list of pairs: [1,1,2,2...]
for i, word in enumerate(input_text_list):
x, y = new_values[i, 0], new_values[i, 1]
plt.annotate(word, (x + .03, y + .03))
plt.title(pre_title + model_name)
plt.xlim(xlim_min, xlim_max)
plt.ylim(ylim_min, ylim_max)
#plt.show()
return plt
Here is an example of a use case of the embed_2d_compare() function:
in_15 = "Relaxed"
in_16 = "Tense"
input_text_list = [in_1, in_2]
plot = embed_2d_compare("textembedding-gecko@001",
input_text_list,
"euclidian",
xlim_min=-0.05,
xlim_max=1,
ylim_min=-0.05,
ylim_max=1
)
plot.show()
Topics to cover later:
- Literature review (that was a practical excersise, not full-scale research)
- Extra metrics
- Phrases distances (context change: hot topic vs hot weather)
References
- OpenAI: visualizing embeddings
- Google: Text embeddings
P.S. Written with a help of GPT-3.5